Tutorial 5: Drafting the Analysis
Contents
![]()

Tutorial 5: Drafting the Analysis#
Good Research Practices
Content creators: Yuxin Zhou, Marguerite Brown, Natalie Steinemann, Zane Mitrevica
Content reviewers: Sherry Mi, Maria Gonzalez, Nahid Hasan, Beatriz Cosenza Muralles, Katrina Dobson, Sloane Garelick, Cheng Zhang
Content editors: Jenna Pearson, Chi Zhang, Ohad Zivan
Production editors: Wesley Banfield, Jenna Pearson, Chi Zhang, Ohad Zivan
Our 2023 Sponsors: NASA TOPS and Google DeepMind
Tutorials Objectives#
In Tutorials 5-8, you will learn about the research process. This includes how to
Draft analyses of data to test a hypothesis
Implement analysis of data
Interpret results in the context of existing knowledge
Communicate your results and conclusions
By the end of these tutorials you will be able to:
Understand the principles of good research practices
Learn to view a scientific data set or question through the lens of equity: Who is represented by this data and who is not? Who has access to this information? Who is in a position to use it?
# imports
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import numpy as np
from scipy import interpolate
from scipy import stats
Video 1: Drafting the Analysis#
Coding Exercise 1#
To explore the relationship between CO2 and temperature, you may want to make a scatter plot of the two variables, where the x-axis represents CO2 and the y-axis represents temperature. Then you can see if a linear regression model fits the data well.
Before you do that, let’s learn how to apply a linear regression model using generated data.
If you aren’t familiar with a linear regression model, it is simply a way of isolating a relationship between two variables (e.g. x and y). For example, each giraffe might have different running speeds. You might wonder if taller giraffes run faster than shorter ones. How do we describe the relationship between a giraffe’s height and its running speed? A linear regression model will be able to provide us a mathematical equation:
speed = a * height + b
where a and b are the slope and intercept of the equation, respectively. Such an equation allows us to predict an unknown giraffe’s running speed by simply plugging its height into the equation. Not all giraffes will fit the relationship and other factors might influence their speeds, such as health, diet, age, etc. However, because of its simplicity, linear regression models are usually first attempted by scientists to quantify the relationship between variables.
For more information on linear regression models, see the Wikipedia page, especially the first figure on that page:
# set up a random number generator
rng = np.random.default_rng()
# x is one hundred random numbers between 0 and 1
x = rng.random(100)
# y is one hundred random numbers according to the relationship y = 1.6x + 0.5
y = 1.6 * x + rng.random(100)
# plot
fig, ax = plt.subplots()
ax.scatter(x, y, color="gray")
# regression
res = stats.linregress(x, y) # ordinary least sqaure
ax.plot(x, x * res.slope + res.intercept, color="k")
ax.set_xlabel("x")
ax.set_ylabel("y")
Text(0, 0.5, 'y')
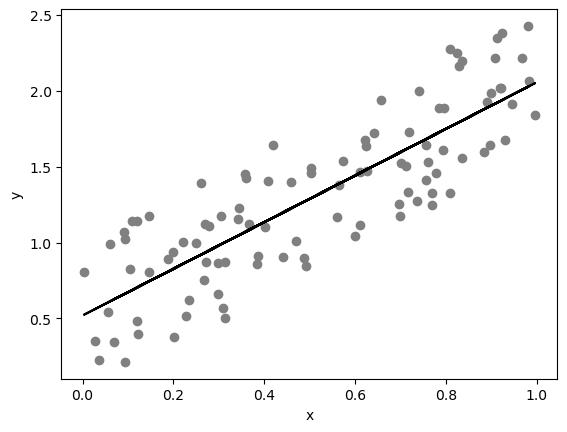
To get a sense of how our model fits the data, you can look at the regression results.
# summarize model
print(
"pearson (r^2) value: "
+ "{:.2f}".format(res.rvalue**2)
+ " \nwith a p-value of: "
+ "{:.2e}".format(res.pvalue)
)
pearson (r^2) value: 0.71
with a p-value of: 3.33e-28
Now that we know how to write codes to analyze the linear relationship between two variables, we’re ready to move on to real world data!